Live · 2025
MacroMentor
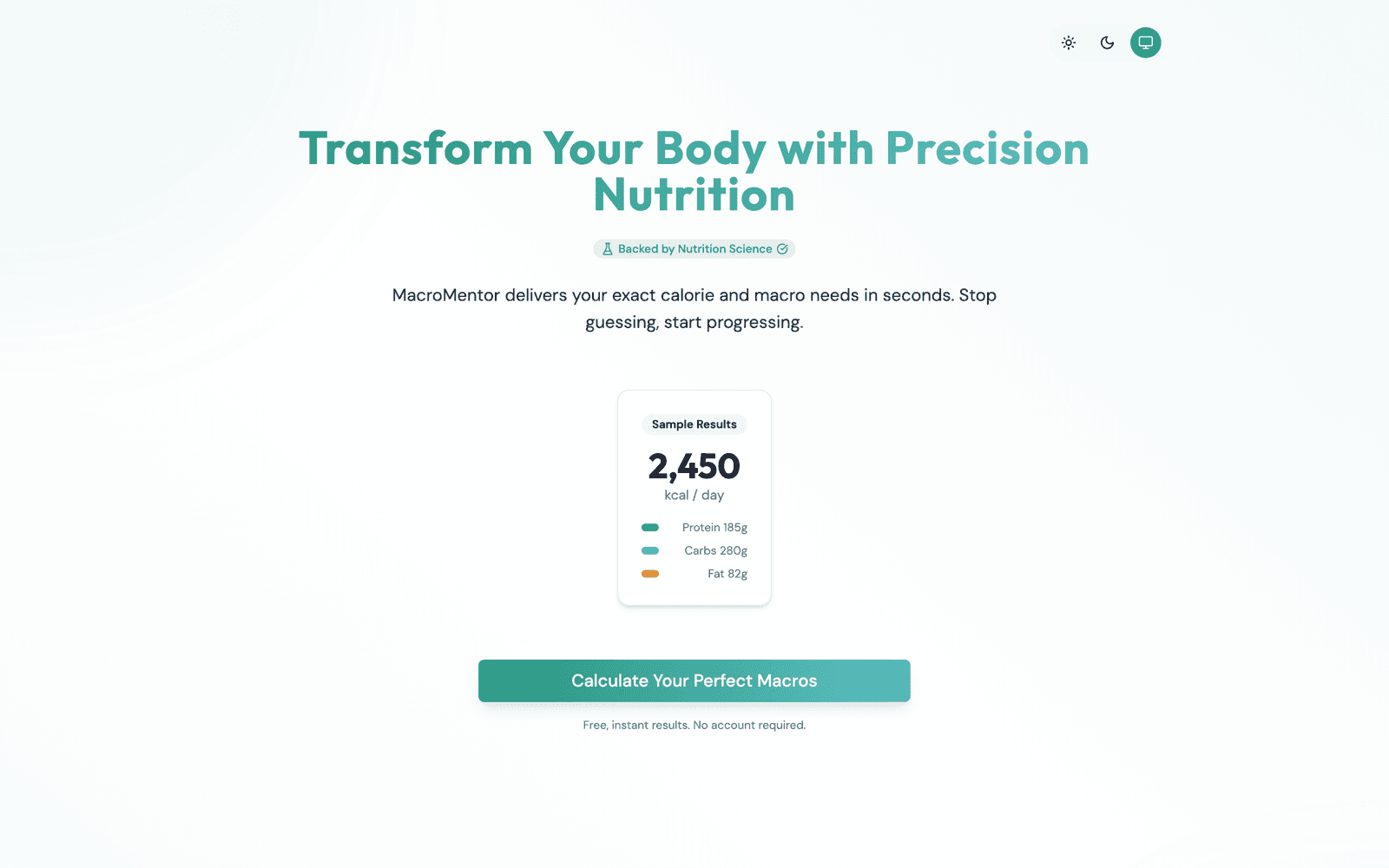
Hyper-personalised calorie and macro calculator
I decided to get healthy and refused to hand the problem to a generic calorie app. Instead I used deep-research AI tools to read the current academic literature on BMR, TDEE, and macro targeting: the kind of synthesis that used to require a dietitian, a sports-science researcher, or a long stack of journal articles. Then I built the calculator I wished existed.
I showed it to several personal trainers before the public launch. They called it amazingly useful. These are people paid to spot bad macro calculators.
It hasn't helped me lose weight yet. The tool works; adherence is its own problem.
macromentor.horizonfall.comgithub.com/adityarajashekaran/macromentorTechnical detail
The BMR formula is tiered by what data the user can actually provide. Cunningham at the top (requires body fat percentage and training experience). Then Katch-McArdle or the Singapore equation depending on body composition data and optional ethnicity input. Then Mifflin-St Jeor as the fallback, with transparent population-level adjustments flagged in the output when they apply.
TDEE is calculated via Physical Activity Level, which separates baseline daily activity from structured exercise rather than applying a single generic multiplier. Calorie targets are goal-calibrated with safety caps built in: 1,200 and 1,500 kcal floors, maximum deficit tied to body fat percentage, refeed recommendations for aggressive cuts. Goals covered: fat loss at multiple rates, muscle gain (clean and aggressive), maintenance, body recomposition. Micronutrient guidance fires for iron, calcium, vitamin D, omega-3, and fibre, with risk flags when waist-circumference thresholds are crossed.
Ethnicity input is handled carefully: optional, explained before the user is asked, only ever applied as a small refinement in the Mifflin-St Jeor tier, skipped entirely when body fat percentage is available, and flagged in the output whenever it was used.
The calculation core is a pure function in calculator.ts, covered by a 43-test Vitest suite. Every tier, every formula branch, and every safety cap has a named test case with expected values recorded.
One method I arrived at the hard way: write the tests for each section first, then build against them. My first attempts let AI build the calculator directly and it kept silently dropping steps: a tier would fire wrong, a cap would not trigger, a macro floor would be skipped. Once the tests existed as a specification, the AI-generated implementation was correct. This is the only reliable way to keep AI honest on a multi-branch calculation engine, and it generalises to any complex AI-built system.